
 NVIDIA anunta integrarea NVIDIA® NVLink™, un sistem de interconectare de inalta viteza, in viitoarele sale unitati de procesare vizuala, ce permite partajarea de date intre GPU si CPU cu o viteza de la 5 pana la 12 ori mai mare decat in prezent. Acest pas va elimina una dintre cele mai importante limitari hardware din prezent si va facilita aparitia unei noi generatii de supercomputere ce vor avea o viteza de procesare de 50-100 de ori mai mare in comparatie cu cele mai performante sisteme de astazi.
NVIDIA anunta integrarea NVIDIA® NVLink™, un sistem de interconectare de inalta viteza, in viitoarele sale unitati de procesare vizuala, ce permite partajarea de date intre GPU si CPU cu o viteza de la 5 pana la 12 ori mai mare decat in prezent. Acest pas va elimina una dintre cele mai importante limitari hardware din prezent si va facilita aparitia unei noi generatii de supercomputere ce vor avea o viteza de procesare de 50-100 de ori mai mare in comparatie cu cele mai performante sisteme de astazi.
NVIDIA va implementa tehnologia NVLink in arhitectura Pascal, succesoarea arhitecturii Maxwell si care va fi introdusa pe piata in anul 2016. Mai mult, noua solutie de interconectare a fost dezvoltata impreuna cu IBM, companie ce va utiliza NVLink in urmatoarele generatii de procesoare POWER.
“Tehnologia NVLink deblocheaza intregul potential al unitatilor de procesare grafica prin imbunatatirea transferului de date intre CPU si GPU, minimizand timpul de asteptare al unitatii vizuale pentru procesarea datelor,” declara Brian Kelleher, vice presedinte senior al GPU Engineering, NVIDIA.
“NVLink permite schimbul rapid de date GPU – CPU si imbunatateste transferul de date efectuat in interiorul sistemului de calcul, astfel incat sa elimine un obstacol cheie in cadrul procesarii accelerate,” spune Bradley McCredie, vice presedinte si IBM Fellow, IBM. ”NVLink le permite dezvoltatorilor sa modifice mai usor aplicatiile de inalta performanta şi analiza de date, astfel incat acestea sa utilizeze potentialul sistemelor accelerate CPU – GPU. Credem ca aceasta tehnologie reprezinta o contributie semnificativa la ecosistemul nostru OpenPOWER.”
Multumita integrarii solutiei NVLink in procesoarele IBM POWER si in unitatile de procesare vizuala NVIDIA Tesla®, ecosistemul centrelor de date POWER va beneficia de intregul potential de accelerare GPU in rularea diverselor aplicatii, de la procese de calcul de inalta performanta, pana la analiza de date si inteligenta artificiala.
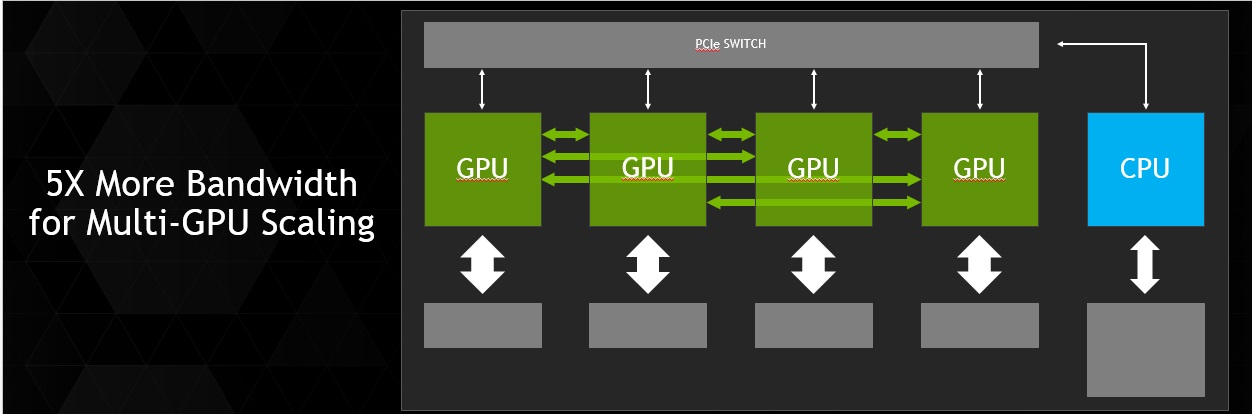
Avantaje fata de PCI Express 3.0
Unitatile de procesare vizuala din prezent sunt conectate la procesoare bazate pe arhitectura x86 prin intermediul interfetei PCI Express (PCIe), ce nu numai ca limiteaza abilitatea GPU-ului de a accesa sistemul de memorie dedicat CPU-ului, dar are şi o viteza de 4-5 ori mai lenta decat sistemele de memorie CPU obişnuite. PCIe este un factor limitativ cu atat mai important in cazul conexiunilor dintre unitatile de procesare vizuala şi CPU-urile IBM POWER, ce dispun de o latime de banda mai generoasa decat in cazul procesoarelor x86. Fiindca NVLink va lucra cu latimea de banda a sistemelor de memorie CPU tipice, sistemul ii va permite procesorului grafic sa acceseze memoria procesorului central la potentialul sau maxim.
Aceasta solutie de interconectare cu banda larga imbunatateşte considerabil performantele aplicatiilor accelerate. Din cauza diferentelor dintre sistemele de memorie – GPU-urile au memorii rapide dar de capacitati reduse, iar CPU-urile dispun de memorii lente, de capacitati mari – aplicatiile accelerate transporta datele de pe mediul de stocare in memoria CPU, iar apoi copiaza aceste date in memoria GPU pentru a fi procesate de acesta. Cu NVLink, transportul de date dintre CPU şi GPU se realizeaza la viteze mult mai mari, rezultand o viteza de lucru mult mai rapida in cazul aplicatiilor accelerate.
Memoria unificata
Viteza imbunatatita a transferului de date, impreuna cu o alta caracteristica denumita Unified Memory (memorie unificata) vor simplifica programarea de aplicatii accelerate GPU. Memoria unificata le permite dezvoltatorilor sa trateze memoriile GPU şi CPU ca şi cum cele doua ar fi un singur bloc de memorie. Astfel, programatorul poate lucra cu date fara a-şi face griji referitor la memoria pe care vor fi stocate.
Chiar daca unitatile de procesare vizuala NVIDIA vor continua sa functioneze prin PCIe, NVLink va fi utilizata pentru conectarea GPU-urilor la CPU-urile compatibile cu aceasta tehnologie, dar şi pentru a oferi conexiuni de banda larga intre mai multe unitati de procesare vizuala din acelaşi sistem. De asemenea, in pofida latimii de banda generoase, NVLink are o eficienta energetica per bit transferat superioara tehnologiei PCIe.
NVIDIA a proiectat un modul pentru gazduirea de GPU-uri bazate pe arhitectura Pascal ce au incorporata tehnologia NVLink. Acest nou modul GPU are doar o treime din dimensiunea placilor PCIe utilizate in prezent pentru GPU-uri. Conectorii din partea inferioara a modulului Pascal ofera posibilitatea conectarii acestuia la placa de baza, imbunatatind design-ul sistemului şi integritatea semnalului.
Solutia de interconectare de mare viteza NVLink va permite dezvoltarea de sisteme de o inalta interdependenta, o cale ce poate conduce spre supercalculatoare cu o mare eficienta energetica ce ruleaza la 1,000 petaflops (1 x 1018 operatii floating point pe secunda), adica mai rapide de 50-100 de ori fata de cele mai performante sisteme ale momentului.
SAN JOSE, Calif.—GTC—25 martie, 2014 — NVIDIA

